Reģistrējieties, lai lasītu žurnāla digitālo versiju, kā arī redzētu savu abonēšanas periodu un ērti abonētu Rīgas Laiku tiešsaistē.


Sensenos laikos, kad internets savienoja galvenokārt akadēmiskas organizācijas, atrast informāciju bija vienkārši. Ja bija nepieciešams kāds pētījums no Kalifornijas Tehnoloģiju institūta, tad vajadzēja doties uz caltech.edu, ja no Masačūsetsas Tehnoloģiju institūta, tad uz mit.edu. Cilvēki pastāstīja viens otram par jaunām adresēm, un to jau nemaz tik daudz nebija – ne adrešu, ne cilvēku, kuriem tās būtu nepieciešamas. Deviņdesmito gadu vidū Tīkls kļuva pieejams arī komercorganizācijām. Tad tas sāka strauji izplesties un jebkurš varēja izveidot mājaslapu gan sev, gan savam sunim. Kaut ko interesantu varēja atrast, apmeklējot interneta meklēšanai veltītus portālus, tādus kā yahoo.com vai specializētās saišu lapas, kur resursi bija jau iepriekš apkopoti un kategorizēti. Tikmēr lapu skaits strauji pieauga un cilvēka spēkos vairs nebija tās ne apskatīt, ne izvērtēt. Lapu saturs mainījās, tās parādījās un pazuda. Domēni tika pārpirkti vai mainīja darbības virzienus. Adrese, kas vēl vakar bija noderīga, šodien varēja izrādīties pilnīgi lieka. Tad talkā nāca meklētāji, kas piedāvāja teksta meklēšanu, balstoties uz tajā ietvertajiem vārdiem. Rezultātā varēja iegūt to lapu sarakstu, kurās atradās meklētie vārdi. Lapu saraksts bija milzīgs, taču to atbilstība gaidītajam – šaubīga. Šo situāciju izmantoja tirgus speciālisti un bezgoži. Lai novirzītu apmeklētājus uz savu uzņēmumu lapām, netika žēloti nekādi līdzekļi. Meklēšanas rezultātus piepildīja pornogrāfija un reklāmas. Arī paši meklētāji rādīja pirmkārt tos rezultātus, par kuriem maksāja reklāmdevēji. Tāda bija situācija brīdī, kad parādījās Google, balta un nevainīga.
Umberto Eko kādā intervijā stāstīja, ka grāmatu pieejamība vairs neesot nekāda problēma. Informācijas mūsdienās ir stāvgrūdām. Grūtāk ir saprast, kuru tieši grāmatu vajadzētu lasīt. Tikai ar gadiem izveidojas nepieciešamās iemaņas, kā noskaidrot autoru, izdevniecību, pārskatīt satura rādītāju un indeksu. Pieredzējis lasītājs pēc dažām lapaspusēm varēs saprast, vai ir vērts lasīt tālāk. Atsauces vienā grāmatā ļauj atrast citus vērtīgus darbus par šo tēmu. Līdzīgi ir ar Google.
Paguglēsim?
Tajā 1998. gada vasarā visi par to vien runāja kā par jaunām biznesa iespējām. Klīda leģendas par privātās garāžās uzbūvētiem interneta serveriem un divdesmitgadīgiem puišeļiem, kas, īstajā brīdī piereģistrējot īsto domēna vārdu un adresi, vienā naktī kļuvuši par miljonāriem. Ierasti lietišķo biznesa presi pārpludināja nopietnu analītiķu sajūsma par jauno dotcom (apzīmējums komerciālas interneta adreses beigu daļai – .com) biznesa fenomenu un nākotni, bet satraukti brokeri dežurēja biržās, lai pārķertu kādas plaukstošas interneta kompānijas akcijas.
Lerijs Peidžs un Sergejs Brins satikās ekskursijā pa Stenfordas universitāti, šķiet, Sergejs bija tikko atbraucis, lai iestātos doktorantūrā, bet Lerijam bija uzdots izvadāt jaunos kolēģus pa universitātes teritoriju. Viņi atceras, ka jau pašā sākumā paspējuši sastrīdēties pilnīgi par jebkuru jautājumu, ko sarunā skāruši. Viņiem nebija vienāda viedokļa nevienā nozarē, izņemot vienu – datu meklēšanu un apstrādi.

Sergejs ir dzimis Maskavā 1974. gadā, taču no Krievijas neko daudz neatceras, viņa ģimene 1979. gadā ebreju emigrācijas vilnī pārcēlās uz ASV, kur matemātikas skolotājs Mihails Brins kļuva par Merilendas universitātes pasniedzēju, bet viņa sieva Jevgēnija sāka zinātnisku darbu NASA Pētījumu centrā. Šķiet, nekāds cits liktenis Sergejam arī netika gatavots – jau sešu gadu vecumā viņam piederēja savs personālais dators, bet 1. klasē viņš ieradās ar mājasdarbu izdrukām, kas 80. gadu sākumā pamatīgi pārsteidza arī amerikāņu skolotājus. Merilendas universitātes bakalaura programmu matemātikā viņš pabeidza pirms termiņa un 1993. gadā ieguva prestižu stipendiju studijām Stenfordas universitātē, kas atrodas Silikona ielejas pašā centrā. Tur viņam piedāvāja iespēju uzreiz iestāties doktorantūrā, savienojot maģistra grāda iegūšanu ar zinātnisku darbu. Studiju laikā viņš piedalījās vairākos kolektīvos pētījumos, izstrādājot autortiesību pārkāpumu uzskaites sistēmu, jauno kinofilmu novērtēšanas reitingu portālu, konverteru no TeX uz HTML zinātnisko dokumentu publicēšanai Tīklā, kā arī meklētāju HTML failu vidē ar jaunu algoritmu izmantošanu. Pēdējo darbu Sergejs veica kopā ar Leriju Peidžu un savā starpā dēvēja par “gugli”, pārveidojot matemātisku terminu googol, ar ko apzīmē vieninieku ar simt nullēm. Pabeiguši studijas, abi kolēģi Bila Geitsa vārdā nosauktajā korpusā vēl pusgadu vadīja šādu mācību kursu:
CS 349: Datu ieguve, meklēšana un vispasaules tīmeklis
Otrdienās un ceturtdienās no 4.15 līdz 5.30
Galvenā korpusa 370. auditorijā
Pasniedzēji: Sergejs Brins un Lorenss Peidžs
pieņem otrdienās un ceturtdienās no 5.30 līdz 7.00 vai pēc iepriekšējas norunas
un
Kursa asistente: Diāna Tanga
416. kabinetā no pirmdienas līdz trešdienai 11.15-12.15
Apraksts
Pēdējo divu gadu laikā ir notikusi cieša sadarbība Tīkla izpētē starp Datu ieguves grupu (MIDAS) un Stenfordas Digitālās bibliotēkas grupu. Šī sadarbība ir vainagojusies WebBase (Tīkla datubāze) projektā, kura mērķis ir saglabāt Tīkla lokālu kopiju (vai vismaz tā būtisku daļu) un izmantot to par izpētes instrumentu informācijas savākšanai, datu ieguvei un citiem uzdevumiem. Tā visa rezultātā ir izstrādāts PageRank algoritms, Google meklētājs, DIPRE algoritms un daudzi citi projekti, kas atspoguļo mūsdienu Tīkla izpētes avangardu (sīkāk - WebBase publikācijās).
Mūsu mācību kursa tēma ir datu ieguve un informācijas saņemšana Tīklā. Vispirms mēs aplūkosim datu ieguves un informācijas saņemšanas pamatus. Otrkārt, aplūkosim jaunākos sasniegumus Stenfordā (PageRank, DIPRE, ...) un citur (Kleinbergs, Mičels,...). Trešais un svarīgākais ir tas, ka studentiem tiks dota iespēja strādāt ar WebBase projektu. Mēs jau esam apstrādājuši lielu daļu WebBase koda, lai ar to varētu strādāt un mēs turpināsim to darīt vasaras laikā. Šobrīd WebBase krātuve sastāv no aptuveni 25 miljoniem mājaslapu, kas aizņem līdz 150 gigabaitiem HTML formātā.
Prasības:
* Labas zināšanas C programmēšanā.
* Darbs ar C++ programmēšanas valodu.
* Statistikas, grafu teorijas un lineārās algebras pamatzināšanas.
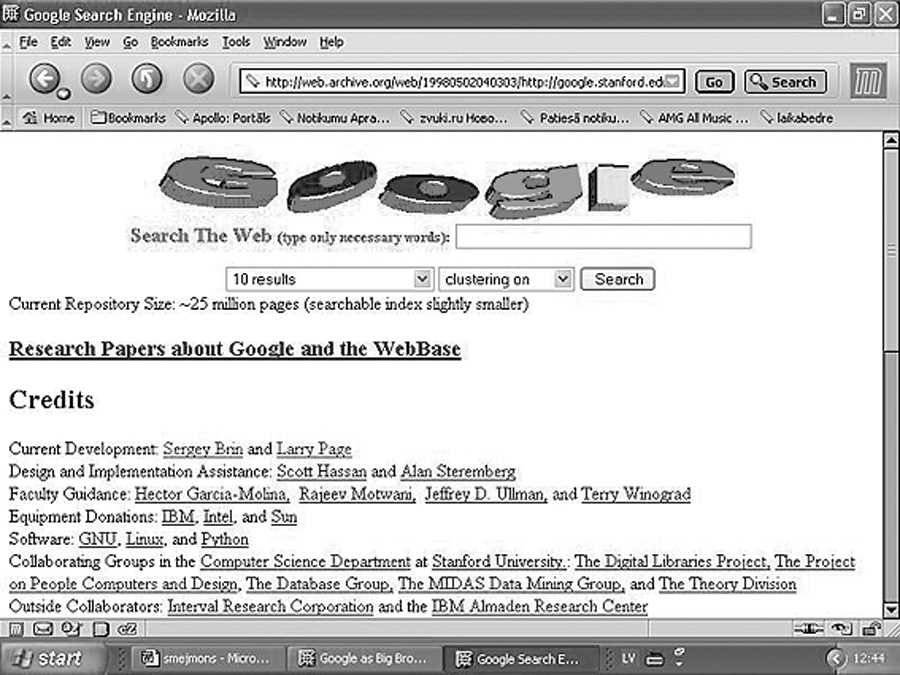
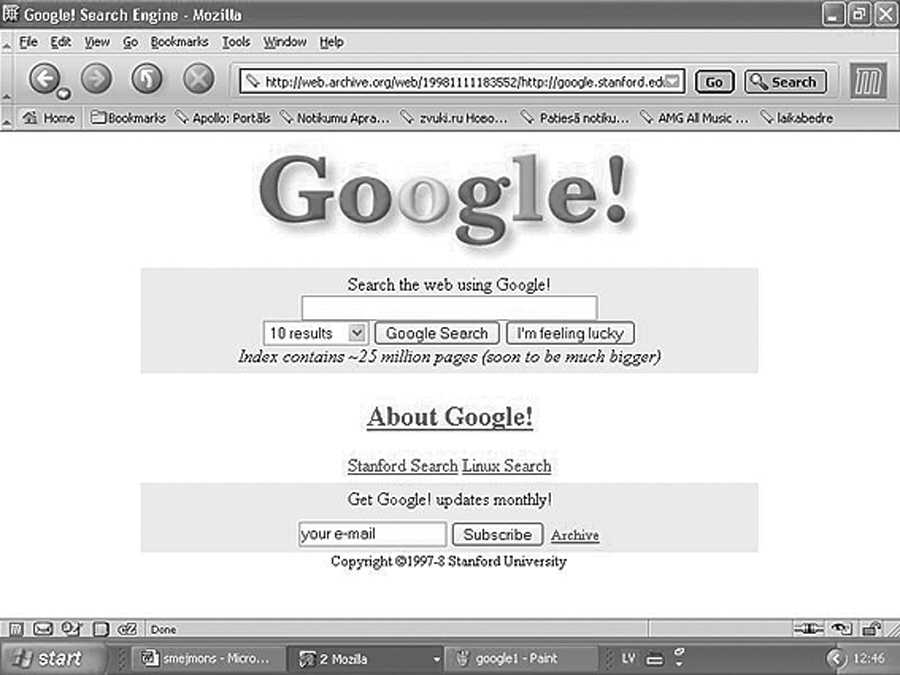
Ieguvuši labas atsauksmes no pasniedzējiem un viņu lapā nejauši ieklīdušiem apmeklētājiem, Sergejs un Lerijs nolēma mazliet nopelnīt un pārdot savu izgudrojumu kādam no jau esošajiem interneta meklēšanai veltītiem portāliem. Apbraukājuši visas tobrīd vadošās šīs jomas kompānijas, kas atradās piecu minūšu brauciena attālumā no Stenfordas, viņi saņēma vienbalsīgu noraidījumu. Īpaši dzēlīgu atbildi sniedza kompānijas Excite vadītājs Džordžs Bells, paskaidrojot, ka meklēšana ir otršķirīgs jebkura interneta portāla serviss, kas nedod nekādus ienākumus. Daudz svarīgāk esot attīstīt citus pakalpojumus, piemēram, bezmaksas elektroniskā pasta servisu. Lieki teikt, ka Excite šobrīd ir bankrotējusi kompānija, kuras portāls ir vairākkārt pārpirkts un darbojas AskJeeves.com paspārnē. Tobrīd arī Stenfordas universitātes vadība sāka izrādīt neapmierinātību ar google.stenford.edu lapas darbību. Atrodoties universitātes interneta pieslēguma Tīklā, šī lapa sāka piesaistīt aizvien lielāku interesi no ārpuses un to apmeklēja 10 tūkstoši cilvēku dienā, noslogojot gandrīz 50% no Stenfordai iedalītā interneta datu plūsmas apjoma. Datorus nācās pārvietot no kopmītnes istabiņas uz draudzenes garāžu. Leģenda stāsta, ka 10. septembrī notika Sergeja un Lerija tikšanās ar Sun Microsystems dibinātāju Endiju Behtolšaimu, viņam līdzīgus cilvēkus zināmās aprindās dēvē par eņģeļiem-investoriem. Pēc īsas meklēšanas algoritma demonstrācijas, eņģelis uzdeva tikai vienu jautājumu: “Uz kā vārda izrakstīt čeku?” Čeks par 100 000 dolāriem tika izrakstīts uz tobrīd vēl neeksistējošas kompānijas Google Inc. vārda.
Šo vārdu tagad pazīst visa pasaule. Vēl vairāk – daudzās valodās stabilu vietu ir ieņēmis darbības vārds “guglēt”. Tas nozīmē – meklēt informāciju Tīklā.
Meklēšanas algoritmi
Ko īsti dara Google? Meklētāja darbs sākas ar datu vākšanu. Tiek ņemta kāda lapa un nokopēta. Tad tiek savāktas visas tajā esošās saites un sekots tām. Šādā veidā tiek apstaigāts viss internets. Programmas, kas ievāc lapas, sauc par robotiem vai zirnekļiem, bet to kustības - par rāpošanu. Savāktās lapas tiek glabātas datubāzē. Pēc dažām nedēļām vai mēnešiem process tiek atkārtots. Kad lietotājs meklētājā ieraksta dažus vārdus, katrs no šiem vārdiem tiek meklēts datubāzē esošajos dokumentos. Rezultāti tiek sakārtoti un nosūtīti atpakaļ lietotājam. Lai gan šobrīd nākas izmantot desmitiem tūkstošu datoru, pašos pamatos šis mehānisms ir vienkāršs. Pieprasījums pirms meklēšanas tiek apstrādāts. No tā tiek izmesti bieži lietoti nenozīmīgi vārdi – es, tu, un, vai. Šo vārdu jebkurā tekstā ir milzums. Kad es analizēju Latvijas interneta lapu vārdu krājumu, populārākie izrādījās – un, ir, to, ar, par, no, vai, es, ka, bet… Šādi sīkvārdi aizņem trešdaļu no visa vārdu skaita un neko daudz nenozīmē, taču apgrūtina meklēšanu. Pameklējiet “to be or not to be”. Google man atbildēja: “Šie vārdi ir ļoti izplatīti un netika iekļauti meklēšanā: to be to be. Ar mazajiem burtiem rakstītais “or” tika ignorēts.” No visas frāzes beigu beigās tika meklēts vienīgi “not”.
Lai meklēšana būtu ātrāka un dati aizņemtu mazāk vietas, var ņemt tikai vārda būtiskāko daļu, piemēram, sakni. Kura ir šī daļa, tas atkarīgs no valodas īpatnībām. Bet valodas, kurās šobrīd tiek izplatīta informācija internetā, ir ļoti dažādas. Izveidot meklētāju, kas strādātu daudzās valodās, vispār ir grūti. Tehniski ne vienmēr vienam baitam atbilst viens burts. UTF kodējumos, kas tiek izmantoti tad, ja vajag vienā tekstā izmantot dažādu valodu rakstību, vienai rakstu zīmei var atbilst līdz pat sešiem baitiem. HTML vai XML datu formātos ir paredzēts aprakstīt, kādā valodā šie dati ir. Ja ziņu nav, var minēt, kā to dara Internet Explorer. Izmantojot zināšanas par burtu biežumu katrā valodā, lielos tekstos to var izdarīt diezgan droši. Grūtības rada specifiskie burti. Vācu “ß” atbilst “ss”, Müller un Mueller ir viens un tas pats uzvārds. “Déja vu” raksta šādi, bet kā atrast informāciju par šo fenomenu, izmantojot ierastos taustiņus? Taču tas arī vēl nav nekas. Ne visās rakstībās ir burta vai vārda jēdziens. Latviešu valodā vārdi tiek atdalīti ar atstarpi vai kādu citu skaidri saprotamu zīmi. Korejiešu, japāņu un ķīniešu valodās atstarpes netiek lietotas. Japānā tiek izmantoti vismaz četri rakstības veidi. No ķīniešiem ievestie hieroglifi, vietējie zilbju alfabēti – hiragana un katakana un latīņu alfabēts. Daži vārdi tiek rakstīti vienā, daži citā, bet ir vārdi, kuri sākas kā hieroglifi, bet beidzas kā katakana.
Lai palielinātu atrasto datu atbilstību lietotāja vajadzībām, tiek izmantotas arī dažādas vārdnīcas. Meklētājs var sameklēt ne tikai attiecīgo vārdu, bet arī tā sinonīmus vai atbilstošas nozares vārdus. Meklētājam noder vārdnīcas, kurās ir teikts, ka šis vārds ir lietvārds vai darbības vārds, kādi ir tā locījumi un atvasinājumi, izplatītākie savienojumi ar citiem vārdiem. Ne visi vienas saknes vārdi ir morfoloģiski tuvi. Tāpat ir frāzes, kuru sastāvdaļas atsevišķi nozīmēs pavisam ko citu, nekā konkrētā vārdu secība.
Kad pieprasījums ir apstrādāts, tas nonāk līdz datu bāzei. Tikmēr robots, kurš vientuļš klīst pa plašo internetu, ir izveidojis sarakstu, kurā atrodamas visas viņa rīcībā nonākušās mājaslapas. Arī tās tiek apstrādātas un glabātas īpašā veidā. Papildus tiek ievākta iespējamā metainformācija par valodu, tēmu un autoru. Teksts tiek atdalīts no marķējuma. Katram dokumentam tiek izveidots unikālo vārdu saraksts. Vārdam tiek pievienota papildus informācija – cik bieži tas atkārtojas šajā lapā, kāda ir tā pozīcija dokumentā. Vārds lapas virsrakstā tiks vērtēts augstāk nekā vārds, kas desmit reizes atkārtots baltā krāsā uz balta fona.
Tad no vārdu saraksta dokumentā tiek veidots apgrieztais indekss, kas parāda, kuri dokumenti satur kādu vārdu. Šis process nav nemaz tik viegls, jo dokumentu skaits iesniedzas miljardos. Meklējot lietotāja pieprasītos vārdus, darbs tiek sadalīts. Viens dators meklē vienu, cits tajā pašā laikā – otru vārdu. Vārdu-dokumentu sarakstā tiek atrasti dokumenti, tad šie dokumenti tiek sakārtoti. Ja tekstā ir daudz meklēto vārdu, dokuments ir vērtīgāks, ja tie ir tādā secībā, kā prasīts, vēl vērtīgāks.
Rezultātus kārtojot, tiek izmantoti arī dažādi metadati. Vēl joprojām vērtīgi ir dati no Yahoo! un DMOZ datubāzēm, kur lapas atbilstību kādai kategorijai ir novērtējuši dzīvi cilvēki. Noderīgs var izrādīties ne tikai dokuments, kurā atrodami meklētie vārdi, bet arī tāds, uz kuru norāda daudzas saites no lapām, kas veltītas meklējamai tēmai. Šādi meklējot Google frāzi miserable failure (nožēlojama izgāšanās), pirmajā vietā atradīsiet ASV prezidenta Džordža Buša oficiālo biogrāfiju. To nodrošina pietiekams skaits (pietiek ar 32) jokdaru, kas savās lapās ievietojuši šādas saites uz Baltā nama lapu: <a href=www.whitehouse.gov/president/gwbbio.html>miserable failure</a>.
Lai šis fenomens, kas nodēvēts par google bombing, turpinātu darboties, attiecīgās lapas ir jāatjauno divas trīs reizes nedēļā, tas ir, saitēm ir jābūt pietiekami svaigām, lai meklētājs tās ņemtu par pilnu. Godīgums datu atlasē, kas sākotnēji bija galvenais Google trumpis, nu ir kļuvis par vājo vietu. Zinot Google darbības principus, iespējams izveidot viltus sistēmu, kas novedīs meklētāju pie īpaši izveidotas adreses. Tā, piemēram, labi zināms ir joks ar frāzi french military victories (franču militārās uzvaras) – atverot lapu, kas parādās Google sameklēto rezultātu augšā (vai, nospiežot izvēli “Es ticu veiksmei” – šī izvēle uzreiz atver to lapu, kas, izejot no Google algoritma, ir visatbilstošākā), lietotājs ierauga lapu, kas izskatās precīzi tāpat kā Google kļūdas paziņojums: “Nav atrasta neviena lapa, kurā būtu lietots meklējamais termins. Jūsu pieprasījumam – franču militārās uzvaras – neatbilst neviens dokuments. Varbūt jūs gribējāt meklēt franču militārās sakāves?” Tikai, ieskatoties šīs lapas adresē, var pamanīt, ka tas nav Google paziņojums, bet gan viltots dokuments, kas atrodas uz servera Melnā albīnā aita, kura īpašnieks ir izvietojis pietiekami daudz saišu citās lapās, norādot uz šo kā visautoritatīvāko avotu meklējamā termina jomā. Skaidrs, ka šādi joki, iegūstot publicitāti, kļūst zināmi arī Google darbiniekiem, taču izslēgt šo lapu no indeksa nozīmētu ne vien cenzūru (ir dzirdēts, ka to Google ir atļāvies nacionālā naida kurināšanas gadījumu sakarā) bet pirmām kārtām tas nozīmētu nepilnīgu un mazāk uzticamu indeksu. Joprojām Tīklā funkcionē joks, kas parādījās Irākas kara sākumā – meklējot terminu Weapons of Mass Destruction (masu iznīcināšanas ieroči), rezultātu augšpusē vai pirmajā lapā parādās kļūdas paziņojums, kas pēc izskata atgādina pārlūkprogrammas paziņojumu par neeksistējošu lapu vai Tīkla nepieejamību: “Masu iznīcināšanas ieroči nav atrodami. Šai valstij, iespējams, ir tehniska rakstura problēmas vai arī jums ir jāpārbauda savu ieroču inspektoru kvalifikācija. Izmēģiniet sekojošu rīcību: uzklikšķiniet šeit, lai mainītu valsts iekārtu, vai arī mēģiniet vēlāk. Ja jūs esat Džordžs Bušs, pārbaudiet, vai esat pareizi uzrakstījis valsts nosaukumu adreses lodziņā (IRAQ)…” un tā tālāk, ar instrukcijām ANO un CIP darbiniekiem.
Galvenā Google un citu publisko meklētāju problēma ir tā, ka joprojām tiek meklēti nevis jēdzieni, bet zīmju salikumi. Kaut arī sistēma ir diezgan sekmīga, tās kļūdainība ir liela. Meklētāju kvalitāti ir iespējams mērīt, izmantojot lielu zināmu datu apjomu un salīdzinot atrasto dokumentu skaitu ar tiem, ko ir atraduši eksperti. Precizitāte tiek mērīta, pārbaudot atrastos rezultātus un novērtējot, cik daudz no tiem atbilst pieprasījumam. Parasti rezultāti nevienā rādītājā nav labāki par 50%. Tas būtu tāpat, kā, pieprasot bibliotēkā grāmatas par bebriem, no astoņām grāmatām, kas ir publicētas par šiem kokgraužiem, tiktu saņemtas četras – un no tām divas par ūdriem vai pienenēm. Lai arī tiek izmantotas dažādas lingvistiskās un statistiskās metodes, meklēšanas gaitā datorā nerodas priekšstats par dokumentu saturu. Pagaidām valoda mašīnai ir par grūtu.
Mazākiem datu apjomiem tiek izmantotas arī citādas metodes. Latent semantic indexing projicē katru dokumentā esošo vārdu kā vektoru savā dimensijā. Ar lineārās algebras palīdzību dažādu dokumentu vektorus var salīdzināt ar pieprasījuma vektoru. Tādējādi tuvi var būt arī dokumenti, kuros neatrodas viens un tas pats vārds, ja pārējais vārdu krājums liecina par to tuvumu. Šī metode ir precīzāka par teksta indeksiem, bet semantic tās nosaukumā nenozīmē izpratni. Interesanta tā ir tāpēc, ka var salīdzināt ne tikai vārdus, bet arī citus datus. Tā tiek izmantota bioinformātikā, medicīnā un attēlu atpazīšanā.
Šo problēmu priekšā niecīgas ir 100 000 datoru apkalpošanas grūtības (tik daudz datoru šobrīd apkalpo Tīkla datu bāzi un ienākošos pieprasījumus) vai tas, ka Google algoritma funkcionalitāte varētu apstāties pie 4 294 967 296 [232] ievāktiem dokumentiem, datoru un programmu arhitektūras dēļ. Algoritmi tiek pastāvīgi uzlaboti un tiek meklētas jaunas pieejas. Viena no tām ir lietotāja personisko datu izmantošana, lai izvēlētos piemērotākas atbildes. Personiskie dati nav tikai vārds, uzvārds un personas kods. Google izmanto daudzu cilvēku elektroniskās vēstules, kuras tiek glabātas tās serverī. Gan Google, gan Microsoft ir gatavi izmantot dokumentus no lietotāju datoru cietajiem diskiem. Tiek krāta informācija par cilvēku meklēšanas paradumiem. Protams, tas viss tiek darīts, lai nopelnītu. Ar teksta un attēlu meklēšanu daudzās kompānijās nodarbojas cilvēces gaišākie prāti. Dažreiz ir jāpieliek lielas pūles, lai uz atbildi būtu jāgaida tikai sekundes daļas, bet meklēšanas sarežģītība nepārtraukti pieaug.
Google no iekšpuses
Lai noskaidrotu, kādi cilvēces gaišākie prāti strādā Google Inc., mēs satikāmies ar Pīteru Norvigu, cilvēku, kura darba pieredzē iepriekšējais ieraksts bija NASA Pētījumu centra vadošais speciālists – divsimt cilvēku liela departamenta vadītājs, kas nodarbojās ar pētījumiem un izstrādnēm sistēmu autonomijas, robotu, automatizēto datorprogrammu un datu analīzes, neiroinženierijas, sadarbības sistēmu un simulatīvo lēmumu pieņemšanas jomā. Kopš 2001. gada novembra viņš ir viens no 60 zinātņu doktoriem, kas strādā Google komandā. Un viņa CV, kas atrodas internetā, sākas ar vārdiem: “Lūdzu netraucēt ar darba piedāvājumiem. Man jau ir pats labākais darbs pasaulē.”

Rīgas Laiks: Kāpēc jūs pārnācāt uz Google?
Pīters Norvigs: Es atnācu šurp, jo uzskatīju to par lielisku iespēju. Google dara pasaulei svarīgu darbu un tas ir aizraujoši – būt par daļu no šī darba, padarīt vairāk informācijas pieejamāku vairāk cilvēkiem. Un arī tīri praktiski tā bija lieliska iespēja. Es zinu, ka daudzi labi inženieri pārnāk strādāt uz Google tāpēc, ka tā ir iespēja strādāt ar šo datubāzi, strādāt ar milzīgu datorjaudu, kas atrodas vienuviet.
RL: Un ko īsti jūs darāt?
Norvigs: Es esmu meklēšanas kvalitātes direktors.
RL: Ko tas nozīmē?
Norvigs: Man ir 34 cilvēku komanda un mūsu uzdevums ir pārbaudīt gatavās atbildes.
RL: Es vienmēr esmu brīnījies, kas nosaka to secību, kādā parādās atbildes uz mana datora ekrāna, kad es kaut ko meklēju internetā.
Norvigs: Okei, tas tieši ir tas, ko mēs ik dienas cenšamies uzlabot. Šo secību nosaka tas, cik lielā mērā atrastā lapa atbilst tam vārdam, ko jūs esat iedrukājis. Un arī tas, cik kvalitatīva šī lapa ir, rēķinot šo kvalitāti attiecībā pret meklējamo vārdu. Tas, cik šī lapa ir uzticama, noderīga.
RL: Kā to ir iespējams aprēķināt?
Norvigs: Tur ir vairākas lietas. Tā metode, ar kuru Google nāca klajā, kad kompānija tika dibināta, bija ideja ņemt vērā saites, kas Tīklā norāda uz attiecīgo lapu. Katra lapa saņem noteiktu “balsu skaitu”, atkarībā no tā, cik citās lapās ir atrodamas saites uz šo. Un tā, kas saņem visvairāk balsu, uzvar. Tas, protams, nav gluži demokrātiski. Ja tu esi lapa, kas ieguvusi zināmu autoritāti, uz tevi norādīs vairāk saišu, nekā uz lapu, kas nav tik laba. Taču, jo vairāk saišu norādīs uz tevi, jo lielāku autoritāti tu automātiski iegūsi. Tāpēc ir vēl vairāki triki, ko mēs izmantojam. Mēs skatāmies, vai meklējamie vārdi parādās pašā lapā vai lapā, kas uz to norāda, mēs skatāmies, vai vārdi parādās virsrakstos un lieliem, trekniem burtiem vai arī sīkiem, maziem burtiņiem.
RL: Un tas viss tiek aprēķināts un ņemts vērā?
Norvigs: Jā.
RL: Bet kas tādā gadījumā ir tas, ko šeit varētu vēl uzlabot?
Norvigs: Es domāju, ka mēs varam strādāt vēl labāk, saprotot gan to, kādas ir lapas, gan to, ko īsti lietotājs vēlas atrast. Tas nav viegli, taču, no otras puses, pieprasījuma vidējais lielums ir divi trīs vārdi. Tā nav gara saruna, kas mums būtu jāanalizē. Un šie pieprasījumi atkārtojas. Cilvēki meklē vienu un to pašu, atkal un atkal. Un mēs mēģinām saprast, kas ir tas, ko viņi patiesībā vēlas izdarīt. Viņi iedrukā vārdus, taču viņiem ir kaut kāda iepriekšēja doma par to, kas, viņuprāt, aiz šiem vārdiem slēpjas. Un mums ir jācenšas uzminēt, ko šie vārdi patiesībā nozīmē. Vai ir vēl kādi citi vārdi, kas nozīmētu to pašu, vai vārdi, ko cilvēki būtu varējuši lietot šo vārdu vietā. Iespējams, ka tas, ko cilvēks meklē, tiek apzīmēts ar kādu precīzu vārdu, ko viņš gluži vienkāršu nepazīst, piemēram, ja tas ir kāds medicīnisks termins. Un mēs viņam varam piedāvāt vairāk atbilžu, ļaujot viņam iemācīties kaut ko jaunu.
RL: Tas ir, pat tad, ja es ierakstu nepareizo vārdu, es vienalga varu nokļūt tur, kur es gribēju?
Norvigs: Jā, mēs pie tā strādājam. Lai jūs saņemtu pareizo atbildi pašā saraksta augšā.
RL: Kā jūs varat paredzēt, ko īsti es vēlos atrast?
Norvigs: Pirmkārt, mums ir lielas priekšrocības, jo mūsu rīcībā ir milzīgi resursi. Mums ir visas šīs lapas, visu meklēšanu rezultāti, ko lietotāji ir saņēmuši agrāk. Un mēs varam teikt – lūk, pagājušoreiz, kad kāds meklēja šo pašu vārdu, viņa izvēle apstājās pie šī rezultāta.
RL: Ak tad redz, kā! Pat tas tiek ņemts vērā? Iepriekšējo meklētāju izvēle?
Norvigs: Jā, zinot viņu reakciju, mēs varam no tā daudz ko mācīties.
RL: Bet tad jau var aiziet tik tālu, ka jūs varat paredzēt, ko cilvēks meklēs kā nākamo.
Norvigs: Jā, tas ir interesanti, lai gan pagaidām mēs ar to vēl nenodarbojamies, mēs tikai uzkrājam visaptverošus statistiskus datus. Bet to visu varētu izmantot, piemēram, zinot, no kurienes jūs esat. Teiksim, no Latvijas. Mēs varam paredzēt, kādu tieši informāciju jūs varētu meklēt, kādas vietas varētu jūs interesēt. Tas viss, arī jūsu iepriekšējo meklējumu biogrāfija, varētu tikt izmantota atbilžu sagatavošanai, taču tur vēl ir daudz jautājumu, kas būtu jāatrisina. Piemēram, privātuma aizsardzība. Vai mēs drīkstam izmantot šo informāciju tikai saistībā ar jums, vai arī to var izmantot visi lietotāji, – tas ir jautājums, kas vēl jāsaprot. Šobrīd labi ir tas, ka jūs varat pateikt savam draugam – iedrukā Google meklētājā šo te vārdu un paskaties, ko tu tur atradīsi. Pagaidām ir tā, ka, ja viņš iedrukās to pašu vārdu, viņš, visdrīzāk, saņems to pašu atbildi, vismaz tuvāko pāris dienu laikā. Bet aizvien vairāk var iznākt tā, kā vienam manam draugam, kurš piezvanīja, lai pateiktu – paskaties, kas šodien ir Amazon.com pirmajā lapā, tur ir brīnišķīgs atlaižu piedāvājums. Bet Amazon.com šobrīd piedāvā pilnīgi personalizētu lapu, kas balstīta uz konkrēta lietotāja iepriekšējo uzvedību. Tas, ka es tur kaut ko redzu, nenozīmē, ka jūs tur ieraudzīsiet to pašu.
RL: Bet kas varētu būt tas ideālais stāvoklis vai mērķis, uz kuru šādam interneta meklētājam vajadzētu tiekties? Kādā Spīlberga filmā bija tāds vīrs, kurš zināja visas atbildes. Vai ir tāda iespēja tuvākajā nākotnē, ka tā vietā, lai meklētu vārdus, es varētu uzdot jautājumus?
Norvigs: Jā, ir cilvēki, kas šobrīd pie tā strādā. Mēs varam paņemt jūsu jautājumu, saprast, kuri ir būtiskie vārdi šajā jautājumā, sameklēt lapas, kas satur šos būtiskos vārdus un sniegt jums rezultātu, kas kaut kādā veidā saturēs atbildi uz jūsu jautājumu. Tā ir interesanta problēma – kā labāk atbildēt uz jautājumu. Mēs varam jums vienkārši uzrādīt attiecīgās lapas, bet varam arī sakārtot informāciju no šīm lapām un sniegt apkopotu rezultātu. Jā – ideāls meklētājs būtu tāds, kurā jūs varat iedrukāt jebkuru jautājumu un saņemt pareizo atbildi.
RL: Izskatās, ka pie tā jums vēl ir jāpiestrādā.
Norvigs: Jā.
RL: Kā tas bija iespējams, ka brīdī, kad Google parādījās Tīklā, pārējie meklētāji neizturēja konkurenci un turpināja piedāvāt salīdzinoši vājākus atbilžu rezultātus. Vai jūs varat paskaidrot, kas tas bija par izrāvienu, ko toreiz izdarīja Google? Ja vien tā nav konfidenciāla informācija.
Norvigs: Svarīgākais izrāviens bija tas, ko es jau pieminēju – tas, ka tika ņemtas vērā saites, kas no vienas lapas norāda uz citu. Tas tika ņemts vērā kā sava veida “balsojums” par lapas kvalitāti. Un tas bija nepieciešams, ņemot vērā interneta īpatnības, to, ka tas ir brīvs savā formā, un jebkurš tajā var ievietot savu informāciju. Ja mēs salīdzinām Google ar agrākajiem meklētājiem, mēs redzam, ka pirmā interneta meklētāju paaudze bija veidota pēc bibliotēku katalogu principa. Bet bibliotēkas ir pavisam cita veida krātuves. Tas, kas nonāk bibliotēkā, jau ir izgājis cauri dažādiem filtriem, tas ir pārbaudīts un kvalitatīvs. Jebkas, ko jūs atrodat bibliotēkā, ir, protams, ne jau līdzvērtīgs kvalitātes ziņā, taču izgājis cauri noteiktai atlasei. Vēl viena atšķirība ir tā, ka bibliotēkā jums nav svarīgi, kādā secībā jūs atrodat nepieciešamo literatūru, jums svarīgāk ir atrast visu ar doto tematu saistīto publikāciju apjomu, ko vēlāk iespējams analizēt. Interneta lietotājs nav zinātnieks, viņam ir svarīgi ātri noskaidrot vajadzīgo jautājumu, visbiežāk viņš paņems pirmo pagadījušos atbildi un nemeklēs, ko par to ir teikuši citi līdz pat Aristotelim. Un tad tā kļūst par problēmu – tas, ka jebkurš var publicēt internetā savas atbildes un jums pašam nākas atsijāt derīgās.
RL: Man ir tāds jautājums – kad es ierakstu Google meklētājā pāris vārdus un iegūstu 13 tūkstoš atbildes ar sazinko, līdz kuram ciparam man ir vērts skatīties, ja mēs runājam par kaut cik jēdzīgām atbildēm? Jo nav taču iespējams un, visdrīzāk, nav nekādas jēgas pārbaudīt visus 13 000 rezultātus.
Norvigs: Jā, šim skaitlim ir jēga tad, ja lietotājs vēlas zināt, uz cik precīzu rezultātu viņš var cerēt. Jo mazāk ir sameklēto atbilžu, jo lielāka iespēja, ka atrastās ir pareizās. Ja mēs runājam par to, cik tālu ir vērts aplūkot saņemtos rezultātus, mēs redzam, ka cilvēki parasti aprobežojas ar kādiem 200 rezultātiem. Tās ir desmit lapas pa divdesmit rezultātiem katrā. Lielākā daļa aplūko pirmo rezultātu lapu un tad, ja neatrod meklēto pirmajos desmit rezultātos, ieraksta meklētājā kaut ko jaunu. Citi paliek pie sākotnējā formulējuma un cenšas atrast vajadzīgo, šķirstot rezultātu lapas. Tas ir tikai stila jautājums.
RL: Kad es lietoju Google, es nezinu, ko īsti jūs zināt par mani. Jūs teicāt, ka ņemat vērā informāciju, kas zināma par lietotāju. Kas ir tas, ko jūs zināt par mani un cik tālu jūsu zināšanas sniedzas?
Norvigs: Neteiksim, ka mēs kaut ko zinātu par jums. Mums ir zināšanas par to informāciju, kas uzkrāta mūsu datubāzēs. Mēs zinām, kādus vārdus jūs iedrukājāt meklētājā, mēs zinām, kādas atbildes jums ir patikušas, ko jūs meklējāt kā nākamo.
RL: Jūs varat mani izsekot? Jūs zināt, ko es daru pie sava datora?
Norvigs: Nē, mēs redzam, ko jūs meklējat ar Google palīdzību. Tad jūs uzklikšķināt uz kādu no saitēm rezultātu lapā, un mēs redzam, kuru no saitēm jūs esat izvēlējies. Mēs, protams, nezinām, ko jūs darāt tālāk vai kādas lapas jūs vēl apskatāt.
RL: Un jūs zināt, no kura datora es to daru?
Norvigs: Mm, mēs zinām, vai tas ir tas pats dators, vai cits, no kura nāk nākamais pieprasījums. Tam kalpo tā saucamie cookies – mazi faili, kas tiek noglabāti uz jūsu datora ar skaitli, kas identificē jūsu datoru kā mūsu lietotāju. Tie neidentificē jūs, mēs nezinām, no kurienes jūs esat, bet mēs zinām, ka tas ir tas pats dators.
RL: Kāds ir reklāmu procents meklētāja rezultātos?
Norvigs: Par to atbild cits departaments. Manā pārziņā ir rezultāti, kas parādās sarakstā, bet reklāma, kas parādās blakus, ir cita departamenta ziņā.
RL: Bet es esmu dzirdējis, ka arī šajā sarakstā kādi pirmie piecpadsmit rezultāti ir nopirkti.
Norvigs: Jūs tā esat dzirdējis, bet tā tas nav.
RL: Taču reklāma, kas parādās blakus stabiņā, arī ir atkarīga no tā, ko es esmu ierakstījis meklētājā?
Norvigs: Jā, reklāmdevējs varētu būt vēlējies, lai viņa reklāma parādās tādā gadījumā, ja jūs meklējat kādus konkrētus vārdus. Jūsu pieprasījums dodas uz divām dažādām datubāzēm. Viena ir Tīkla lapu datubāze, bet otra – reklāmas lapu datubāze, kurā norādīts, kurš reklāmdevējs vēlējies, lai viņa sludinājums parādītos līdzās konkrētiem pieprasījumiem.
RL: Ja jums ir 3 miljardi lapu, kā jūs sekojat tam, kādas izmaiņas cilvēki izdara savās lapās?
Norvigs: Mēs atjaunojam visu indeksu pilnībā reizi mēnesī. Taču to informāciju, kas, mūsuprāt, ir svarīgākā, mēs atjaunojam ik dienas. Un dažkārt biežāk. Piemēram, ziņu lapas tiek atjaunotas ik stundu.
RL: Bet reizi mēnesī jūs pārskatāt visu? Un cik cilvēku ar to nodarbojas? Jūs teicāt, ka jums ir 34 darbinieki?
Norvigs: Nē, mans uzdevums nav šis. Ar to nodarbojas cits departaments. Mums ir trīs galvenie departamenti. Mans nodarbojas ar meklēšanas kvalitātes uzlabošanu. Cits – ar Tīkla datubāzes atjaunošanu. Tajā strādā apmēram tikpat daudz cilvēku. Trešais – ar reklāmu identificēšanu un ievietošanu rezultātu lapās.
RL: Un kas ir šie cilvēki, kas nodarbojas ar Tīkla pārstaigāšanu?
Norvigs: Viņi visi ir datorzinātnieki. Dažādās specialitātēs. Pamatspecialitāte ir lielo sistēmu darbība. Tas ir darbs vairāku tūkstošu datoru sistēmās. Svarīga nozare ir statistika, datu apstrāde, apmācība.
RL: Labi, bet kā jūs pamatotu, kāpēc kādam būtu jāizvēlas lietot Google, nevis kāds cits meklētājs?
Norvigs: Nu, mana atbilde par šīm citām kompānijām nebūs visai objektīva…
RL: Bet tomēr.
Norvigs: Pirmkārt, Google ir specializējusies tikai meklēšanā. Yahoo! vai MSN dara vēl daudz citu lietu – viņi piedāvā jums jaunākās ziņas, spēles un daudz ko citu. Mēs koncentrējamies tikai uz meklēšanu. Es nesaku, ka tās citas lietas nebūtu svarīgas, bet meklēšana ir mūsu pamatuzdevums. Mums ir izveidota atsevišķa komanda, kurā tiek algoti labākie speciālisti, kādus iespējams atrast. Tā ir mūsu specialitāte – atrast labākos rezultātus. Otra lieta ir tā, ka tajā, ko mēs darām, mēs cenšamies būt maksimāli godīgi pret mūsu klientu. Un es zinu, ka cilvēki to augstu novērtē. Mēs skaidri formulējam, kas ir reklāma un kas ir algoritma ceļā iegūtie rezultāti. Citiem šī darbība ir aizplīvurotāka. Mēs neņemam naudu par to, lai kāds atrastos rezultātu sarakstā augstāk par citiem, lai arī ir kompānijas, kas to pieņem. Mēs neprasām naudu par to, lai jūsu lapa atrastos mūsu indeksā, lai arī ir kompānijas, kas to dara. Mēs iekļaujam indeksā visas lapas, kuras ir to vērtas.
RL: Bet kādā veidā jūs iegūstat šo lapu kopijas? Jūs vienkārši ņemat un nokopējat to, ko es esmu ievietojis savā lapā?
Norvigs: Ievietošana internetā ir publikācijas veids. Mēs nokopējam šo publicēto informāciju savām vajadzībam, uzskatot (un tas nav tikai mūsu uzskats), ka drīkstam to brīvi izmantot fair use jeb godīgas izmantošanas nolūkos. Turklāt Tīklā darbojas noteikti protokoli, kuros jūs varat norādīt, ja nevēlaties, lai jūsu dokumenti tiktu kopēti. Jūs varat norādīt: “Es nevēlos, lai mana lapa tiktu indeksēta,” vai “Es nevēlos, lai šo dokumentu būtu iespējams kopēt” utt. Un mēs ievērojam šīs prasības, ko izvirza persona, kas attiecīgo dokumentu publicē Tīklā.
RL: Tātad mans jautājums radies aiz nezināšanas. Bet tomēr, ja jums ir 3 miljardi lapu, cik daudz mega-gigabaitu tas aizņem?
Norvigs: Tie ir daži desmiti terabaitu.
RL: Viss Tīkls?
Norvigs: Tas atkarīgs no tā, kādā formā to uzglabā, kādus dokumentus izvēlas, ko saspiež, bet aptuveni tā tas ir.
RL: Neizklausās nemaz tik daudz.
Norvigs: Jā, bet tā ir tikai tekstuālā daļa, kas neietver attēlus, filmas un citus apjomīgus failus. Mums gan ir atsevišķs attēlu meklētājs, taču pamatbāzē mēs neglabājam attēlus. Mēs nokopējam daļu attēlu, ko uzglabājam saspiestā, samazinātā veidā un tad norādām saiti uz vietu Tīklā, kur var atrast oriģinālo attēlu. Bez tam, mums ir nepieciešamas vairākas Tīkla datubāzes kopijas. Ja būtu tikai viens lietotājs, mums pietiktu ar vienu kopiju, taču bieži ir vairāki lietotāji, kas vienlaikus meklē vienu un to pašu vārdu vai lapu. Mums ir 200 miljoni pieprasījumu dienā.
RL: Bet jums taču nav nepieciešami 200 miljoni kopiju?
Norvigs: Nē, nav.
RL: Cik tad?
Norvigs: Es nezinu.
RL: Bet tas cipars ir desmitos, simtos?
Preses sekretāre: (Iejaucas.) Teiksim tā – mums ir vairākas kopijas.
RL: Ja jums būtu jāsalīdzina Google ar kādu dzīvnieku, kurš tēls tam piestāvētu visvairāk?
Norvigs: (Samulst.)
RL: Kaut kas rāpojošs? Zirneklis?
Norvigs: Jā, tas varētu būt kaut kas rāpojošs... Kaut kas draudzīgs, izpalīdzīgs, kaut kas tāds, kas ir cik iespējams vienkāršs.
Lielais brālis 2003
Google idejas pamatā ir vecais labais Apgaismības laikmeta priekšstats par zināšanām kā absolūtu vērtību. Vispārēja informācijas pieejamība, vārda un domas brīvība, domājošo cilvēku sadarbība kopīga mērķa vārdā – tas viss joprojām aizkustina zinātnisko laboratoriju iemītniekus un kalpo par iedvesmu ideālo sistēmu radīšanai. Pirms divdesmit gadiem šādā veidā dzima internets, bet pirms sešiem gadiem tapušais Google meklētājs ir tikai loģisks tradīciju turpinājums, savā ziņā pat interneta otrā elpa, kas gluži tāpat kā daudzi labie nodomi, ir bruģējis ceļu jaunām problēmām. Katrai utopijai ir sava antiutopija un, ieskatoties rūpīgāk, var ievērot, ka pagājušogad no interneta lietotājiem saņemtais tituls Lielais brālis 2003 ir pelnīts. Statistika rāda, ka vairāk nekā 80% gadījumu, kad lietotājs atver kādu interneta lapu, viņš to ir atradis ar Google palīdzību. No mazas, neatkarīgas un godīgas idejas Google ir kļuvis par absolūtu monopolistu jomā, kas ir visjūtīgākā pret jebkādu monopolu – informācijas iegūšanas jomā.
Google bija pirmie, kas sāka izmantot cookies ar maksimāli ilgu darbības termiņu – līdz 2038. gadam. Interneta un datoru dzīvē tas nozīmē mūžību. Šobrīd šādu praksi izmanto praktiski visi meklētāji. Google ieviesa šo standartu un neviens neuzdrošinājās tam iebilst. Tagad ikreiz, kad lietotājs atver Google lapu, viņa datorā tiek nolasīts identifikācijas numurs, kam Google datubāzē atbilst apjomīga informācija par iepriekš izdarītajiem pieprasījumiem, izvēlēm, interesēm. Ja kādam šī informācija liktos pietiekami svarīga, to iespējams izmantot visdažādākajiem mērķiem. Piemēram, arestēt jūs par aizliegta rakstura informācijas meklēšanu.
Google reģistrē pilnīgi visu informāciju, kādu vien var iegūt par lietotāju – viņa datora identitāti, IP adresi, no kuras izdarīts pieslēgums, laiku un datumu, meklētos terminus un pārlūkprogrammas uzstādījumus. Pietiekami, lai noskaidrotu, kur jūs atrodaties un ar ko nodarbojaties.
Google neizmanto nekādu datu dzēšanas vai noilguma sistēmu. Jebkura informācija, kas nonāk viņu datubāzē, tiek uzglabāta mūžīgi un ir viegli pieejama. No Google nekad nav saņemta pamatota atbilde par to, kādam nolūkam viņi uzkrāj informāciju, ko šobrīd praktiski neizmanto. Aktuālo pieprasījumu modificēšanai tie nav svarīgi.
Jaunu Google pakalpojumu klāstā ir programmu papildinājumi, piemēram, pārlūkprogrammai pievienojams rīks, kas, vienreiz saņēmis lietotāja piekrišanu, turpmāk darbojas bez brīdināšanas – atjauninot uzstādījumus, lejupielādējot jaunu versiju un sniedzot informāciju par lietotāja datora uzstādījumiem. Faktiski tiek radīta situācija, kurā lietotāja datora saturs kļūst zināms Google darbiniekiem, viņam pašam to nepamanot.
Galu galā, pati Google Tīkla datubāze, kas satur kopijas no lielākās daļas internetā publicētajām lapām, ir apšaubāma no juridiskā viedokļa. Vienreiz nokopētu lapas saturu, ko lapas īpašnieks vēlas mainīt, viņš nevar no šīs datubāzes atsaukt. Kļūdainu, mainījušos vai pārāk privātu publikāciju saturs kļūst par Google datubāzes beztermiņa īpašumu. Veids, kādā lapas īpašnieks var izvairīties no iekļūšanas datubāzē, ir ievietot specifisku paziņojumu lapas kodā, kurā būtu teikts “noarchive”. Par šādu iespēju ir informēti tikai speciālisti, pārbaudīt, vai tas tiek ievērots, ir praktiski neiespējami, turklāt no juridiskā viedokļa strīdīgs ir jautājums, vai lapas pieejamība meklētāja robotam var būt pamatizvēle. Tas ir, vai robotam pieejamām nevajadzētu būt tikai tām lapām, kuru īpašnieki ir izdarījuši apzinātu izvēli, pievienojot attiecīgu apstiprinājumu lapas kodā. Protams, tad datubāzē būtu daudz mazāk lapu, taču tās būtu daudz kvalitatīvākas un nerastos privātās informācijas apdraudējums. Viegli iedomāties lietotāju, kurš vēlētos ievietot savā lapā fotogrāfijas no ģimenes viesībām un par lapas adresi informētu tikai savus draugus un radiniekus, taču negribētu, lai šīs fotogrāfijas būtu atrodamas jebkuram ar visvienkāršākā meklētāja palīdzību. Visbiežāk interneta iespēju apžilbinātais cilvēks nemaz nenojauš, cik lielā mērā viņa privātā dzīve ir mainījusies jau no tā brīža, kad viņš pirmo reizi atvēris pārlūkprogrammu, adreses lodziņā iedrukā draugu ieteikto, viegli iegaumējamo adresi: www.google.com.